This Is What You Need To Know About Indexing Pages With Infinite Scroll
- 30 March, 2020
- Jason Ferry
- SEO

In the latest Javascript SEO Office Hours Hangout, Martin Splitt of Google responded to a question regarding infinite scrolling and avoiding indexing of scrolled content like it was actually a part of the major content. Now, what should SEO professionals and site owners know about this?
Infinite Scrolling
Infinite scrolling is a method to continue providing similar content to users. A JavaScript will notice when the user is getting near to the page’s end and shows additional content for your website visitor to read through.
However, the problem is when Google notices the additional content and assume it to be part of the main content. That would be a tragic result as it would probably result to lower rankings.
Questions by the lead developer of Search Engine Journals, Vahan:
“…We have implemented infinite scroll on mobile. In the past we had it on the desktop. My concern is would Google index the infinite scroll articles as part of the main article which is first?
The Ajax URL for each of the page queries has a no-index applied. Is there any guarantee that the appended content will not be indexed as a part of the main web page?”
Martin Splitt’s response:
“The answer is it depends on how it is implemented and how we see it in the rendered HTML.
I would highly recommend checking out the testing tools to see the rendered HTML because it depends a lot on how you build your infinite scroll and how we can discover additional content.
But if it’s like for instance using some sort of link that tells us to go to another URL and then that URL is no-indexed then we would not see that content.”
Martin seemingly refused to state definitively if Google sees the additional content or it does not. His recommendation that this ought to be checked utilising tools from Google is the simplest way to confirm how Google is rendering a site.
Martin Splitt didn’t talk about it, but Google’s Mobile Friendly Test will show the rendered page’s HTML. Therefore, in case Google is indexing the additional content, then it might be displayed in the HTML section of the rendered page results.
While Martin did not point it out, it’s pretty clear that the tool is an exact representation of the rendered web page.
Vahan also said:
“The feature is implemented in the following way, like when you scroll down it loads the article through AJAX at some point like when you are about to end reading the article.
But the AJAX URL which sends the content of the next article has a noindex header tag ( x-robots-tag: noindex ) applied. So that makes me somehow confident that appended content will not be indexed.
But I would like to like how I can make sure that if next scroll the articles will not be indexed as a main part of the article.”
Again, Martin mentioned that he cannot say for sure and that this is one thing that needs to be tested in Google’s tools.
Martin’s answer:
“I don’t know. I’m not fully sure how we see the rendered HTML.
Use the testing tools, specifically the URL inspection tool can help you figure out how the rendered HTML looks like if rendered HTML somehow still contains the additional content because the viewport has changed or something like that then we would index it as part of the main page as in like the page that you’ve seen.
And then no-indexing that doesn’t really help that much. “
Issues that can come with infinite scrolling, according to Martin:
“It can also be that you accidentally no-index the content that was previously on the page so that you might end up no-indexing too much.
I would always test these things and look at the rendered HTML. The rendered HTML tells you what we are seeing. You can use the URL inspection tool to see what we have crawled, so you see it in the crawled rendered HTML.
But you can also use the live test to see what we see if we would do it again.
So it depends really is the answer in that case.”
What Martin Splitt Has To Say About Two Waves Of Indexing And Crawling
Google has talked about the two waves of indexing and crawling in the past, particularly in terms of Javascript processing. Now, Google’s Martin Splitt has something to say about this.
He gave a tip a before that it is disappearing. However, Martin says there’s no such thing.
Martin explained in a JavaScript SEO hangout at the 16:31 mark that "First things first, there's no such thing as the second wave of crawling-ish." He added that by calling it that originally, it caused some issues. He also stated "The wave is an oversimplification that is coming back to us with interesting implications every now and then".
So that’s it.
YouTube Community’s forum discussion.
Update: Some people are having doubts about Martin’s statement, but he just responded on Facebook stating "It's all an oversimplification of what happens in the pipeline. There definitely isn't two waves of crawling. Indexing is a lovely can of worms, but yeah... not exactly two waves of indexing either".
Update 2: Further concerns answered on Twitter in relation to indexing and crawling:
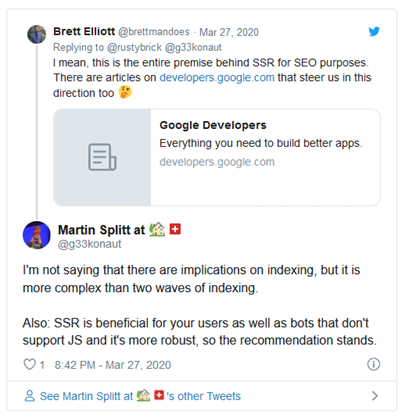
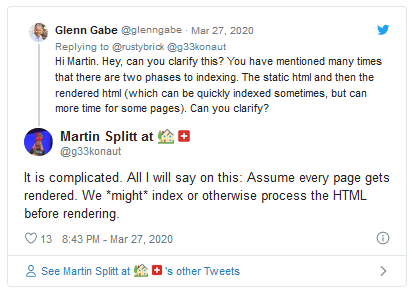
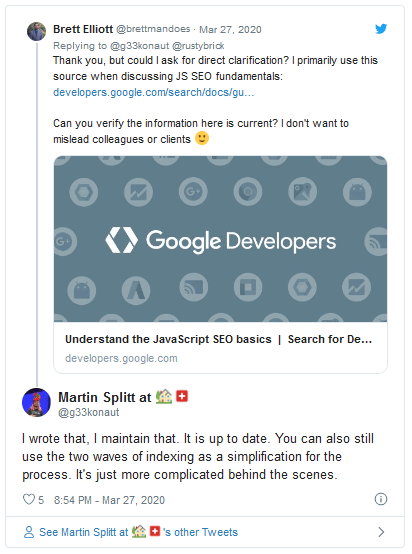
Details in this SEO UK blog were gathered from https://www.searchenginejournal.com/google-martin-splitt-indexing-infinite-scroll/357812/ and https://www.seroundtable.com/google-no-two-waves-indexing-29225.html?. For further information, just visit these links.
By seeking the assistance of the best SEO companies offering their services today, you will have valuable information on how you can optimise your website for traffic and rankings. To know how we can help, head out to Position1SEO.














